



Quickies:
Derrick Schultz is a generative artist who you should follow on Instagram. Every year he does a run of Valentine’s Day cards; this time around he’s got a collection from his GAN (generative adversarial network, a particular flavour of artificial intelligence) work. Go buy ’em.
Amusingly, the most-clicked link from my previous issue, Fact Checking is Table Stakes, went to the Twitter profile of CNN fact-checker Daniel Dale, whose Sisyphean undertaking I remarked on somewhat sardonically. Anyway, he just wrote a summary of the last four years. This doesn’t have to do with anything else; I just thought it was funny that that was the link people clicked the most.
I realized this morning that I haven’t gone swimming in the ocean since New Year’s Day (my wingman is a new parent and it’s too dangerous to do by myself, so pool time for me). Click to see footage from the FauxPro strapped to my head, before I geriatrically turned it off.
I Have Discovered Twitch

I have found my calling as a Twitch streamer, which I will be using mainly for live coding sessions. I cribbed this idea from Al Sweigart (author of Automate the Boring Stuff with Python), but got the boost from watching fellow designer Chappell Ellison play video games for a spell (she: “just jump in and do it!”). My first surprise was how sophisticated the tooling is: not quite like conventional video editing software, more like a mini CNN control room console—i.e., built for mixing real-time AV.
COVID-era conference presentations would actually be pretty sweet with one of these. I am currently using OBS, if anybody wants to try. You will immediately see what I mean.
My motivation for streaming something so utterly quotidian as programming is precisely because it is quotidian: it is the everyday work of somebody who does the kind of work I do. If you don’t do this kind of work yourself, or spend a lot of time around people who do it, how software actually gets made might be a mystery. I have been concerned for some time about the opacity of my process, so I’m laying it bare, with all the snark and the swearing that typically accompanies the process, even when nobody is watching.
What I have found, from my minuscule sample, is streaming does wonders for my productivity. Programming reduces to turning fuzzy thought and language into formal statements, and just sitting there typing in silence is not very interesting, so one is impelled to provide some running commentary. I no doubt mumble to myself whether the camera is running or not, but when people are watching, not only do I feel like I have to narrate the process, but also vocalize my rationale for just about everything. This I have found leads to interesting (perhaps to some?) digressions and forces me to recall why I hold the positions I do about various ideas, processes, tools, people, companies, whatever.
This running commentary is not nearly as intrusive to the task as I had anticipated—certainly no more so than checking Twitter periodically. The format of a session, with a definitive start and end, and some rough goals around what is supposed to happen in between, also makes it easier to concentrate.
Updating an Internet Draft
I began my streaming experiment with some utterly mundane maintenance. Last summer I wrote my first Internet Draft, which was about to expire later this month.
An I-D (Internet Draft) is the first stage of the bulk of the standards that define the Internet. Anybody can write one of these and submit it for initial commentary, where it lasts six months until it is either updated, abandoned, or formally submitted to the editor. If accepted, the draft becomes an RFC (Request for Comments), which is a de facto standard, and as close to a formal standard as most of them get.
My I-D pertains to the extremely mundane subject of Universally Unique Identifiers, or UUIDs. Irrespective of your background, you have no doubt seen these things if you have used a computer for any significant time in the last 20 years. They look like this:
9c5729f3-5213-48b2-827d-53bd92cb8509
UUIDs are useful because they are a way of putting a handle on a piece of information without having to think up a name for it. They are also big enough (2 to the 122nd power, or 5.3 undecillion—that’s trillion trillion trillion—positions per algorithm, of which there are currently five) that you can generate them without having to worry about hitting the same one twice, anywhere in the world (hence “universally unique”).
The problem with these things is there are certain places I want to put them where they just don’t fit. Either they are too long for the slot I want to put them in, or they aren’t the right “shape”: a common constraint in computing is identifiers must start with a letter, and five eighths of the time, a UUID does not. My contribution was to design an alternative, shorter representation that carries the same content—so it can be matched to the original—while preserving certain useful UUID properties✱, and introducing other desirable properties, like ensuring they always begin with a letter of the alphabet.
✱ Some people in the biz may not be aware that UUIDs have a
versiontucked into the first character of the third segment, andvariantbits embedded in the first character of the fourth (which is why the effective entropy of UUIDs is 122 bits, not 128). You can read these off just by looking at them. I made sure this property was preserved, albeit analogously.
The alternative representations are shorter because they represent the same data in higher bases (the originals are hexadecimal, or base-16). Here is what that UUID above looks like, transformed according to the spec I wrote:
EnFcp81ITiyJ9U72Sy4UJIin base-64, which is always 22 characters long,E5NgsnkX4ADFUTPH3AZ4yWIin base-58, which is slightly longer at 23 characters, useful for when your identifiers can’t have hyphens in them,etrlst42scofse7ktxwjmxbijiin base-32, the longest at 26 characters, trades its size off for being fully case-insensitive.
Now, people have been encoding UUIDs in higher bases for a while; indeed many UUID-generating modules ship with a base-64 encoding function. My contribution is the shifting out of the version and variant bits to use as “bookends”, that guarantee the symbol will always start with an alphabetical letter, without having to introduce any characters that lengthen the symbol without conveying any of its content. This keeps these identifiers as short as they can possibly be.
(I have to pad the base-58 representation, which is not a consistent length, or in some cases it would be indistinguishable from base-64.)
This is an example of a problem I had myself and am certain other people have had as well, and saw value in writing down both the spec and two reference implementations (which I needed for myself anyway), to save both the individual and collective pain of wheel-reinvention. For anybody who was watching, I also went through the Internet Draft submission process.
This unfortunately was prior to me figuring out how to turn on recording, which Twitch leaves off by default. No matter, I will almost certainly be doing more in Internet Draft land.
Sharpening the Swiss-Army Knife
While I doubt this kind of work gets very many people excited (though I bet a vanishingly small number of you are thrilled), this is an input into some more palpable (and streamable) work that has been slowly accumulating over the past decade: a sort of breadboard for experimenting with things I would like to see happen in Web content management.
RDF::SAK, which stands for (I suppose) “Resource Description Framework✱ Swiss-Army Knife”, is currently a pile of parts that I use to generate, among other things, my own website. I should really turn it into a standalone static-website-generating tool like Jekyll or Eleventy.
✱ RDF, of course, is the grammar of the Semantic Web, with which this tool is completely suffused. This is an example of an application that is designed around an exchangeable data format that I was discussing in a previous article.
Expect some streams that feature developing, packaging, and using this tool in the near future.
Sugiyama-o-rama
My last two streams had to do with me implementing the Sugiyama framework for drawing directed graphs, which I’m doing from a pile of academic papers. This is more or less what powers the product GraphViz, but I need finer-grained access to the functionality than GraphViz (or anything else, believe me I looked) can provide, so I’m writing the algorithm from scratch (from the papers, because the GraphViz source is unintelligible).
This project actually got me thinking about something really ambitious that has been beaning around in my head for years: a very old idea called literate programming. Academic papers about algorithms often feature pseudocode that is decomposed hierarchically from the outside in, and exposed in an order for the maximum benefit of the reader—which is not how you typically organize an actual program, at least past the point of being manageable. What these papers tend to omit are the finer-grained details of a working implementation. It would be very cool to revive this technique using 2021 kit, to make beautiful papers with examples that actually run. (There are contemporary languages that offer a “literate mode”, but I’m thinking something a lot more hypertext-y, single-source-document-pipeline-y.)
(Check out the archived Sugiyama stream on Twitch or on YouTube.)
I Wanna Draw Some Graphs
My motivation for painstakingly implementing the Sugiyama algorithm is because I want to make a new custom visualization for this monstrosity of an otherwise extremely useful tool:
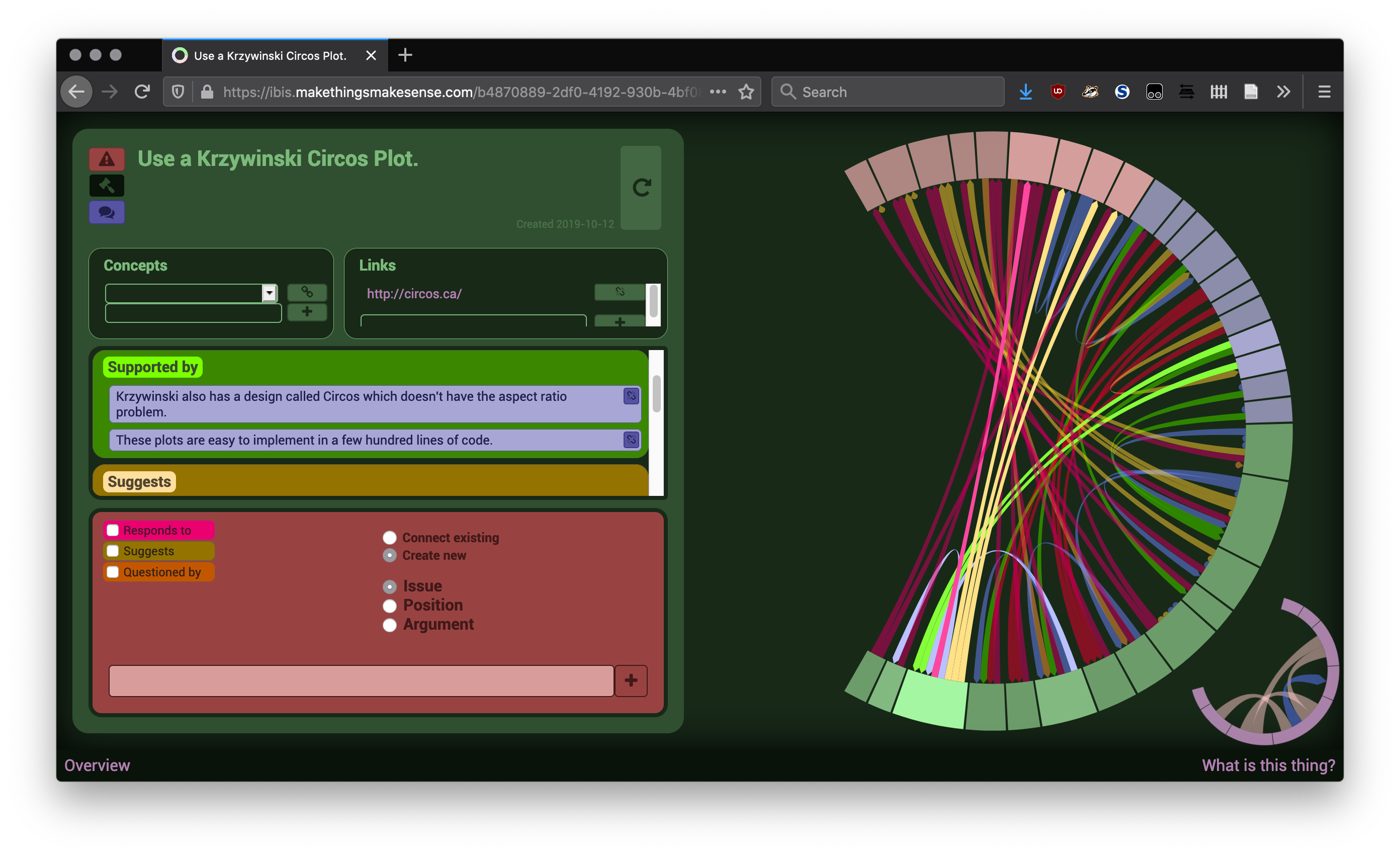
I have been stalled on this thing for years because, well, mainly because I wrote it in a language that would be way harder to continue in than just rewriting it in a better one. I haven’t started, though, because of the sheer amount of time it would take to come up with a visualization people wouldn’t run screaming from. I recently decided on a strategy I’m pretty sure is going to be sweet as hell, so that’s what got me (reluctantly) implementing Sugiyama.
What is it, you ask? It never meant to be more than an experiment for some boring technical stuff, but what it does is map out issues—what needs to be addressed in a situation, how to address it, and why (or why not). I have mentioned it in previous articles and will no doubt mention it more; it is yet another application that is a thin wrapper around publicly-specified, losslessly-exchangeable data.
Anyway, once I have my Sugiyama implementation I can have my new visualization, and the rest of the rewrite will be pretty breezy. This tool (or at least its non-monstrous successor) is an important part of a project management framework I will have to tell you about another time, but I’m excited to be finally moving forward again on it.
Again, I’m streaming at twitch.tv/doriantaylor. As always, feel free to share this newsletter with anybody you think will enjoy it.